Construyendo un Event Storage
- netoec84
- Arquitectura
- Nov 05, 2019
- arquitectura, CQRS, Event Sourcing
Cuando utilizamos event sourcing, como parte de su funcionamiento se realiza el almacenamiento de eventos con el fin de realizar la reconstrucción del estado de una entidad a partir de un conjunto de eventos almacenados.
En el presente artículo se mostrará un ejemplo de implementación de un Event Storage con varios de los problemas que suelen ser comunes al momento de realizar dicha implementación. Se debe considerar que aunque el ejemplo muestra una solución que no es altamente eficiente, sin embargo, satisface la necesidad de un gran porcentaje de aplicaciones.
Un Event Storage puede utilizar con almacén de información: archivos, base de datos relacionales, bases no sql, blob storage, etc, para este caso se hará uso de una base de datos relacional dado que se pretende evitar varios problemas técnicos que no forman parte de este ejemplo, como podrían ser: modelos de confirmación de transacciones, tipo de almacenamiento de datos para obtener un buen desempeño en la lectura.
Estructura
Un Event Storage básico puede representarse en base de datos relacional utilizando solo dos tablas:
Tabla Event
| Columna | Tipo |
| AggregateId | Binary(16) |
| Data | Blob |
| Version | Int |
Esta tabla representa el registro de eventos. Existirá un registro (fila) por evento en esta tabla y el evento en sí se almacenará en la columna Data de la tabla.
El evento se almacenará utilizando algún mecanismo de serialización, aunque el uso del patrón memento puede ser altamente ventajoso para este tipo de problemas.
Esta tabla contiene la cantidad mínima de columnas requerida para implementar el Event Storage, sin embargo se pueden agregar más columnas como: la fecha y hora en la que se realizó el cambio, o metadatos con información relevante del contexto asociado al cambio de estado.
Los metadatos pueden incluir información como el nombre de usuario que inició el cambio, la dirección Ip, nivel de permisos, etc.
La columna Version es utilizada para almacenar el número de versión de cada evento, en la mayoría de los casos un número entero incremental funcionará, así cada evento que se almacena tendrá un número de versión incrementada. El número de versión es único y secuencial solo dentro del contexto de un agregado dado, està información es relevante para asegurar la consistencia
La columna AggregateId es la llave foránea que debe ser indexada, esto nos lleva a la siguiente tabla que es la tabla
Tabla Aggregate
| Columna | Tipo |
| AggregateId | Binary(16) |
| Type | Varchar |
| Version | int |
La tabla Aggregate representa los agregado existentes en el sistema, cada uno de ellos debe contener un registro en esta tabla. Junto con el identificador hay una desnormalización del número de versión actual. Esto se debe a una optimización, ya que podría derivarse de la tabla Events, pero es mucho más rápido consultar la desnormalización que consultar la tabla de Events. Este valor también se utiliza en la verificación de concurrencia optimista.
Para este ejemplo, también se incluye una columna [Type], que corresponde al nombre completo del agregado que se almacena. Es útil por varios motivos, por ejemplo procesos de debug, sin embargo no es necesario para la creación de un Event Storage básico.
Operaciones
Un Event Storage es mucho más simple que los otros mecanismos de almacenamiento de datos dado que no admiten consultas de propósito general. El Event Storage en su nivel más simple tiene dos operaciones, lo que hace que el almacenamiento de eventos sea más simple que la mayoría de mecanismos de almacenamiento de datos, esto también facilita su optimización.
La primera operación es obtener todos los eventos para un agregado. Es extremadamente importante que los eventos se ordenen en el mismo orden en el que fueron escritos, el número de versión se puede utilizar para este propósito. Todo esto se puede hacer simplemente utilizando una consulta de nuestro sistema de gestión de bases de datos relacionales.
SELECT * FROM events WHERE aggregate_id = '' ORDER BY version;Esta es la única consulta que debe ejecutar un sistema productivo contra el Event Storage. Una posible segunda consulta que podría ser de utilidad es el limitar el conjunto de resultados en función de una fecha para conocer el estado de un objeto en un punto en el tiempo, pero generalmente un sistema en producción no debería realizar este tipo de operaciones.
La otra operación que debe soportar el Event Storage es la escritura de un conjunto de eventos de un Raíz Agregado. Esto se puede realizar por código o mediante un procedimiento almacenado. Se prefiere utilizar un procedimiento almacenado o código SQL generado dinámicamente que contiene sentencias de control sobre un proceso de inserción que realice la ejecución de múltiples consultas de ida y vuelta. El pseudocódigo para el proceso de inserción se lo puede observar a continuación:
BEGIN
version = SELECT version FROM aggregates WHERE aggregate_id = ''
IF version IS NULL
INSERT INTO aggregates version = 0
END
IF expectedversion != version
RAISE concurrency problem
FOREEACH event
INSERT event WITH incremented version number
UPDATE aggregate with last version number
END TRANSACTIONLa operación de escritura también es relativamente simple, aunque encontramos algunas sutilezas dentro de ella. El proceso básico es:
- se verifica si existe un agregado con el identificador único que debe usar
- si no hay uno, lo creará y considerará que la versión actual es cero
- luego, intentará hacer una prueba de concurrencia optimista con los datos recibidos para insertar, si la versión esperada no coincide con la versión real, generará una excepción de concurrencia
- siempre que las versiones sean las mismas, se recorrerá los eventos que se están guardando y los insertará en la tabla de Events, incrementando el número de versión en uno para cada evento
- finalmente actualizará la tabla Aggregates con el nuevo número de versión actual del agregado
Es importante tener en cuenta que estas operaciones se realizan en una transacción, dado que es necesario garantizar la concurrencia optimista funcione en un entorno distribuido.
El contrato para un Event Storage se puede definir con la siguiente interfaz:
public interface IEventStore {
void SaveChanges(Uuid AggregateId, int OriginatingVersion, IEnumerable<Event> events);
IEnumerable<Event> GetEventsFor(Uuid AggregateId);
}Aunque no es un tarea trivial el crear un Event Storage para utilizarlo en un ambiente productivo, los conceptos generales detrás de un Event Storage son relativamente sencillos. Sin embargo, hay una optimización muy importante que debería existir en la mayoría de los sistemas y es el concepto de “Instantánea rodante” o “Rolling Snapshot”.
Rolling Snapshots
Los Rolling Snapshots evitan la necesidad de cargar todos los eventos al realizar una consulta para reconstruir un Agregado. Son una desnormalización del agregado en un punto dado del tiempo. Un cambio en la lógica de consulta y una tabla adicional son todo lo que se necesita para agregar la funcionalidad de snapshots al Event Storage.
Tabla Snapshot
| Columna | Tipo |
| AggregateId | Uuid |
| SerializedData | Blob |
| Version | int |
La tabla Snapshot es sencilla. Consta de la columna SerializedData que contiene la versión serializada del agregado en un momento dado. Los datos serializados pueden estar en cualquiera de los muchos esquemas posibles, binarios, XML, texto sin formato, json, etc. La decisión sobre cómo serializar las snapshots depende realmente del sistema que se esté construyendo. Se incluye un número de versión con el snapshot, que representa qué versión del agregado.
Para crear un snapshot, se debe introducir un proceso que maneje su creación. Este proceso puede vivir fuera del servidor de aplicaciones como un proceso en segundo plano y puede existir un solo proceso en ejecución o muchos dependiendo de las necesidades debido al rendimiento. Todos los snapshots ocurren de forma asincrónica. La siguiente figura muestra una arquitectura conceptual incluyendo el proceso [SnapShotter].
ToDo: Insertar gráfico
El [SnapShotter] se encuentra bajo el Event Storage y consulta periódicamente cualquier Agregado que necesite crear un snapshot porque ha superado el número permitido de eventos. Esta consulta se puede hacer con bastante facilidad en Event Storage uniendo la tabla Aggregates a la tabla Snapshot utilizando la columna AggregateId.
La diferencia se calcula restando la última versión en la tabla Snapshot de la versión actual utilizando la cláusula where para que únicamente retorne los agregados con una diferencia mayor que algún número.
Esta consulta devolverá todos los agregados que se crearán en la tabla Snapshot. El SnapShotter luego iteraría a través de esta lista de Agregados para crear los snapshots (si se usan múltiples SnapShotters, el patrón de Competing Consumer funcionará bien).
El proceso de creación de un snapshot implica que el dominio cargue la versión actual del agregado y luego tome un snapshot de la misma. La creación del snapshot se puede hacer de muchas maneras. Una vez que se ha tomado el snapshot, se vuelve a guardar en la tabla de Snapshots para que las consultas tengan el snapshot disponible.
Muchos utilizan la funcionalidad de serialización disponible con la plataforma de desarrollo que utilizan con buenos resultados, aunque el patrón Memento es bastante útil cuando se trata de snapshots.
El patrón Memento (o serialización personalizada) aísla mejor el dominio con el tiempo a medida que cambia la estructura de los objetos del dominio.
El serializador predeterminado suele tener problemas para el manejo de versiones cuando se libera una nueva estructura del dominio (los snapshots existentes deben eliminarse y recrearse o actualizarse para que coincidan con el nuevo esquema). El uso del patrón Memento permite el control de versiones separadas del esquema de snapshots del propio objeto de dominio.
Ten en cuenta que cuando el SnapShotter se da cuenta que el Raiz Agregado necesita que se realice un snapshot carga el Agregado y toma el snapshot. Desafortunadamente, puede suceder que mientras hacía esto, uno de los clientes realizó un cambio en el mismo Agregado. Como el snapshot depende de la posición dentro del log de eventos, recibiría una falla de concurrencia optimista. La respuesta fácil sería simplemente repetir el proceso, pero ¿qué pasaría si fallara nuevamente? El snapshot de un Agregado muy utilizado podría terminar en una situación en la que tendría una probabilidad muy baja de escribir realmente snapshot con éxito.
Al separar los snapshots en su propia tabla y asociarlas a una versión del agregado, se resuelve este problema. No es necesario ordenar los snapshot, los snapshots ni siquiera necesita estar en la última versión, el snapshot que se toma es válido para la versión en la cuál se generó.
Los snapshots son una heurística que mejorará drásticamente el rendimiento de muchos sistemas, aunque no todos los sistemas necesitan snapshots. En general, se recomienda manejar el desarrollo sin snapshots, ya que siempre se puede introducir más tarde como una simple mejora del rendimiento del sistema.
Event Storage como una Cola
Se sabe que los eventos que salen de un dominio también son un [Modelo de integración]. Muy a menudo, estos eventos no solo se guardan, sino que también se publican en la cola donde se envían de forma asincrónica a los suscriptores dentro del mismo sistema o para otras aplicaciones (la generación de reportes es un buen ejemplo).
Un problema que existe con muchos sistemas de publicación de eventos es que requieren una confirmación de dos fases entre cualquier almacenamiento que estén utilizando (relacional o de otro tipo) y la publicación de sus eventos en la cola.
La razón por la que se necesita la confirmación en dos fases es que podría ocurrir una catástrofe durante el pequeño período de tiempo entre la confirmación de la escritura en el almacenamiento de datos y la confirmación de la escritura en la cola.
Si ocurriera una falla durante este período, el mensaje no se publicaría en la cola (o en la otra dirección, se puede publicar pero el cambio no se guardaría). Si ocurriera cualquiera de los casos, los suscriptores de los eventos no estarían sincronizados con el productor.
La confirmación en dos fases puede ser costosa, pero para los sistemas de baja latencia hay un problema mayor cuando se trata con esta situación. En general, la cola en sí es persistente, por lo que el evento se escribe en el disco dos veces en la confirmación de dos fases, una en el Event Storage y otra en la cola persistente.
Dado que la mayoría de los sistemas tienen dos escrituras no es tan importante, pero si tiene requisitos de baja latencia, puede convertirse en una operación bastante costosa, ya que también forzará búsquedas en el disco. La siguiente figura ilustra la confirmación en dos fases entre el almacenamiento de datos y la publicación en una cola.
ToDo: Insertar gŕafico
Se podría solucionar este problema escribiendo solo en una cola y luego «algo» en el otro lado de la cola debería actualizar el almacenamiento de datos con los cambios representados por los eventos, sin embargo, esto tiene algunos problemas. El mayor problema es que no todos los eventos podrán escribirse en el almacenamiento, se ha introducido una consistencia eventual y es posible que ocurra un problema de concurrencia optimista en la escritura de los eventos. Tratar este problema en un sistema de producción no es trivial.
Por otro lado, muchas soluciones hacen lo contrario, usan el almacenamiento de eventos como una cola. Agregar un número de secuencia a la tabla Events discutida anteriormente permite usar el Event Storage como una cola. La siguiente tabla ilustra el cambio en el esquema de la tabla Events.
| Columna | Tipo |
| AggregateId | Binary(16) |
| Data | Blob |
| SequenceNumber | Long |
| Version | Int |
La base de datos aseguraría que los valores de SequenceNumber serían únicos e incrementales, esto se puede hacer fácilmente usando un tipo de incremento automático.
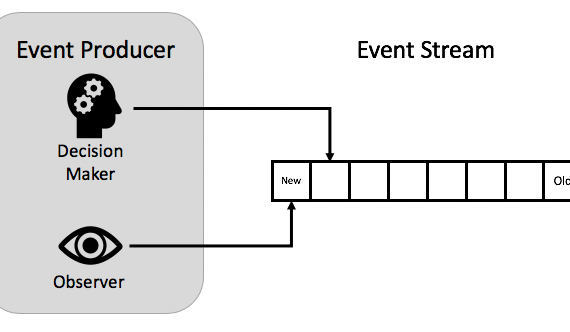
Debido a que los valores son únicos e incrementales un proceso secundario puede estar atento a la tabla de Events y publicar los eventos en otra cola. El proceso de «estar atento» simplemente tendría que almacenar el valor del número de secuencia del último evento que había procesado, incluso podría actualizar este valor con un compromiso de dos fases que lleva la actualización y la publicación a la cola en la misma transacción. Este proceso se puede ver en la siguiente figura.
ToDo: Insertar gráfico
La responsabilidad ha sido retirada del procesamiento inicial de una manera segura. La publicación puede ocurrir de forma asíncrona a la escritura real. Esto reduce la latencia de completar la operación inicial, también limitará el número de escrituras de disco en el procesamiento de la solicitud inicial a uno.
Esta estrategia puede ser extremadamente valiosa cuando se trata con requisitos de baja latencia, ya que permite que gran parte del trabajo en el procesamiento inicial se descargue a otro proceso de forma asincrónica y segura, hay poca diferencia si la publicación ocurre como parte del procesamiento inicial o de forma asincrónica, ya que generalmente los mensajes se publican de forma asincrónica de todos modos, el uso de Event Storage como cola solo aumenta el tiempo hasta que el mensaje se publique ligeramente, esto puede verse como un aumento leve del SLA.